


The fundamental truth is that, in software engineering, your job isn’t done until your code is running successfully in production. However, that doesn’t mean that code has to run perfectly. While reliability is a key responsibility for engineers, organizations can’t expect perfect reliability and uptime.
As part of this, organizations need to know how, when, and why their systems fail. This is where observability and Service Level Objectives (SLOs) come into play.
We’re joined again by Liz Fong-Jones, Principal Developer Advocate at Honeycomb.io to discuss why organizations need observability, how SLOs are vital to understanding product outages, and how to use both of those principles to reduce burnout.
People, not tools
In the modern software engineering landscape, microservice architectures are increasingly common. However, that presents a new challenge in the risk of engineer burnout from the ever increasing cognitive load. Not only that, but as companies strive to proactively address issues before they impact users, organizations are working with ever growing layers of complexity.
Previously, organizations might have addressed this by hiring platform engineers or Site Reliability Engineers (SREs) to handle reliability issues, but that doesn’t always address the issue. Instead, that often entrenches the issue of having all the relevant information to manage services within a single person or team.
The truth is that the answer to this issue doesn’t lie in buying software engineering tools. Buying DevOps isn’t the answer to running production and maintaining a valuable feedback loop. Having more tools and microservices adds more tests, and in turn, more complexity. While tools like Kubernetes can have numerous benefits for DevOps, organizations shouldn’t adopt these tools simply because software engineering experts tout their benefits. Liz says:
“Honestly, I think this is where my thinking aligns with Humanitec. We need to think about how we’re providing people with the ability to solve problems. It all starts with your people. If you adopt a tool-first methodology, then you might lose sight of who uses those tools.”
While tools will inevitably add complexity, that complexity shouldn’t lead to engineers spending more time firefighting than fixing the overarching problem.
So, how do organizations get to a state where tools facilitate production instead of stressing out engineers?
The key is identifying what needs to change within the production cycle and then investigating what tools will help to facilitate that journey. Organizations should invest in people, culture, and processes first.
This is where the concept of production excellence, or ProdEx, comes into play.
Understanding production excellence
Production excellence is about running systems reliably and without burning out engineering. However, it’s not something that organizations can implement and leave to run in the background. ProdEx needs to be planned with KPIs that are aligned with engineering happiness. Not only that, but it needs to be a cross-disciplinary effort across a wider range of teams than just engineering.
There are four key elements of ProdEx culture that need to be implemented:
- Measure to understand when systems are too broken,
- Debug systems to understand why they’re broken,
- Collaborate with other teams to repair the damage,
- Fix what’s going on inside the system and eliminate unnecessary complexity.
Liz explains that it’s important to specify when systems are too broken to be functional:
“Our systems are always failing. There’s always some microscopic way our systems are broken. We understand that not every blade of grass on our lawn is going to be green, so why are we expecting every query to succeed? All that really matters is that the lawn is green enough to send our kids or dogs out to play on.”
SLOs and SLIs (Service Level Indicators) help organizations to measure system performance in a common language that can be understood by engineers, product owners, and customers. However, for an SLO to be valuable, it needs to be aligned with customer journeys and the context around how those journeys move through the system.
SLOs and error budgets
One such SLO that organizations can use is the measurement of system availability.

To do this, engineers need to define what counts as a good event. For example, Liz says “I might decide my service is running acceptably if it’s serving HTTP code 200 requests in <100ms.”
Engineers then need to define eligible events, which typically refers to all non-artificial events, and the timespan the measurement should be set over. Ideally, this should encompass 30 - 90 day periods.
Overall, this would lead to having a set SLO that states 99.9% of events over 30 days are good.
Of course, while engineers will always aim to make their systems as good as possible, 100% uptime isn’t possible. Even outside of technical issues, customers will themselves experience issues with cellular networks or ISPs that can cause requests to fail. Pursuing 100% uptime will inevitably lead to development slowing to a crawl as engineers are called to fix the system every time there’s an error.
Instead, organizations have to decide what a reasonable error rate is for their organization. SLOs are designed to be reasonable goals that optimize services for a combination of reliability and product velocity. So, instead of having engineers on call to handle every single outage, they can instead focus on the overall trend.
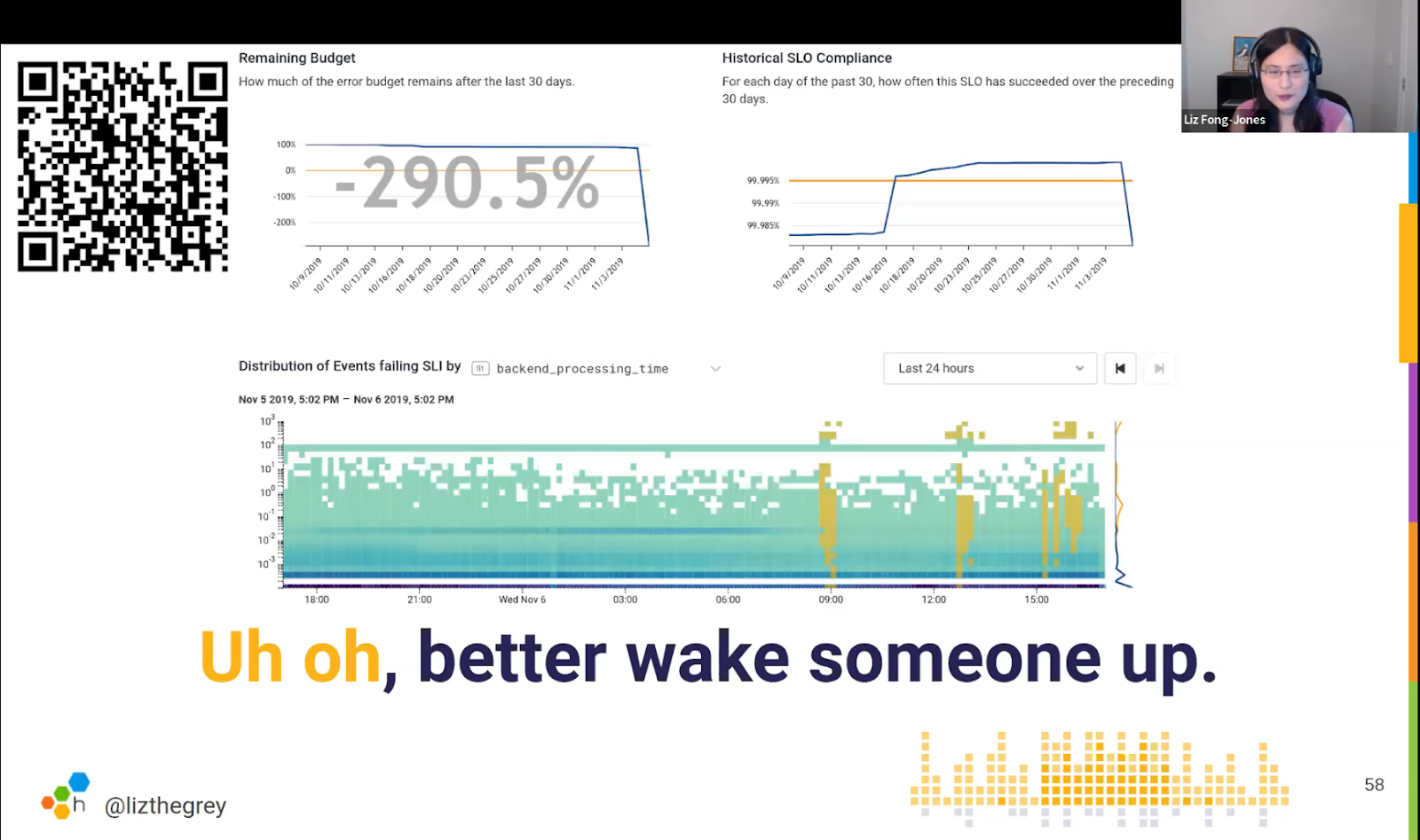
By defining what’s acceptable in SLOs, engineers can reverse that to understand acceptable error rates. For example, given a target of 99.9% uptime, one in 10,000 requests is therefore allowed to fail. If the system is serving 100 million requests a month, that gives the system an error budget of 100,000 failed requests.
By that calculation, 100 failed requests an hour will take 1,000 hours to run out, so it doesn’t need to be handled by the on-call team immediately. However, 10,000 failed requests an hour will run through the error budget in a single day which warrants alerting the engineer on call.
So, SLOs can be used to ensure that organizations are only alerting engineers when there’s a genuine problem.
Observability and velocity
In addition, SLOs allow organizations to understand whether engineering is moving too fast or too slow. By having a quantitative idea of what reliability is within a system, engineers have a better idea of whether they’ve got scope to add new features. Liz says:
“If you’ve got some error budget left then sure, flag on a new feature for 1% of users. If it goes wrong you can roll it back without worrying about blowing your error budget. But if you’ve got a lot of reliability problems, agreeing on an SLO in advance means you can tell your project manager that you’re violating the reliability threshold. It doesn’t matter how many new features you ship - customers won’t trust them unless they’re reliable.”
Observability gives engineers valuable insights into how their services are running, allowing them to reduce how long it takes to diagnose and fix problems that might be entirely novel. In mature systems, bugs may only appear in production, so the ability to debug in production is vital to maintaining uptime and user confidence. By having data around how systems are operating, organizations enable a core analysis loop that allows engineers to form and test hypotheses about systems as a mechanism for diagnosing problems.
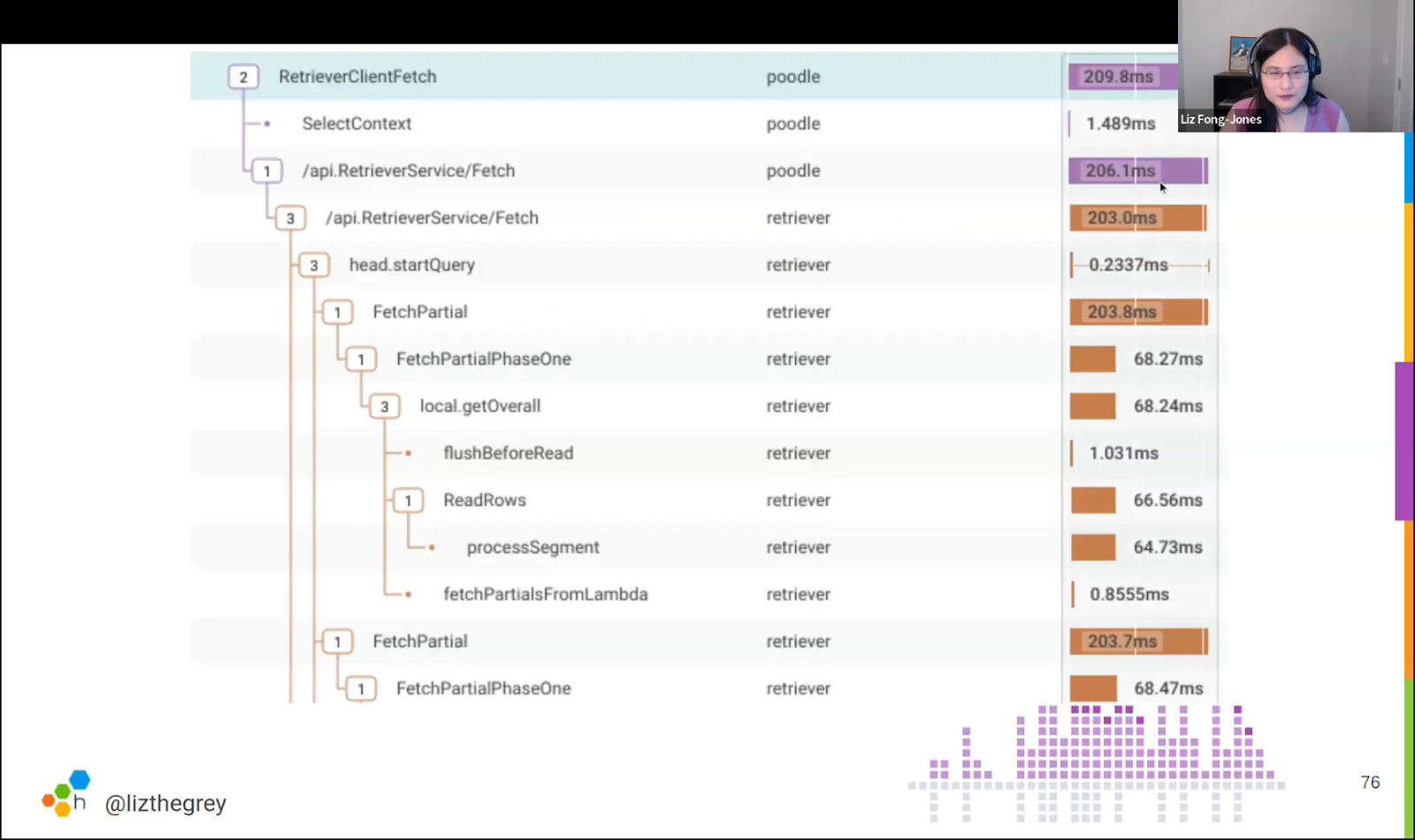
Engineers also need observability over the context of the issue to understand what was happening as the failure occurred. It’s not just about seeing what’s correlating with or causing these errors, but also the variance between slow and fast requests. Having observability in place allows engineers to pinpoint exactly where requests are failing and lead them towards figuring out why.
So, while SLOs help engineers understand when systems are too broken, observability allows them to explain why and remediate those issues as soon as possible. They both work in tandem towards production excellence.
ProdEx as a cultural discipline
SLOs and observability are powerful factors but they need to be backed up with cultural change. Organizations need to encourage collaboration and knowledge sharing across teams so the burden of fixing issues doesn’t sit on the shoulder of a handful of experienced engineers.
Similarly, these teams should put these skills into practice before they’re needed to ensure that everyone works together smoothly. Engineers need to feel safe enough to step back if they’re getting burned out knowing that someone else is available to take their place with no detriment to the situation at hand.
On top of that, organizations need to build a culture where engineers feel safe to speak up and ask questions. As Liz puts it, “we’re not just working with present coworkers, but we need to learn from our past coworkers to leave things better for future engineers.”
Finally, risk analyses are a vital ProdEx practice. Liz explains:
“We need to think about the frequency of risks and how bad they are. The MySQL server will inevitably go down and there’s not much we can do about that. But what we can affect is how bad that outage is. So, does it take 3 hours to fix our system, or do we failover? Does it affect all users or just 2% of them? We need to prioritize the most significant risk first.”
By using SLOs to define good and bad events, organizations can create effective risk assessments that address issues that will prevent them from achieving those objectives. On top of that, observability means that those issues will take less time to fix, making outages shorter so they affect fewer users. Investing in both of these practices ensures that future outages will have an increasingly reduced impact on users, allowing organizations to build more reliable systems.
Thanks to Liz Fong-Jones for joining us again and delivering another insightful meetup. Make sure to watch the recording for yourself and, if you’re interested in diving deeper, check out her book on observability engineering.
