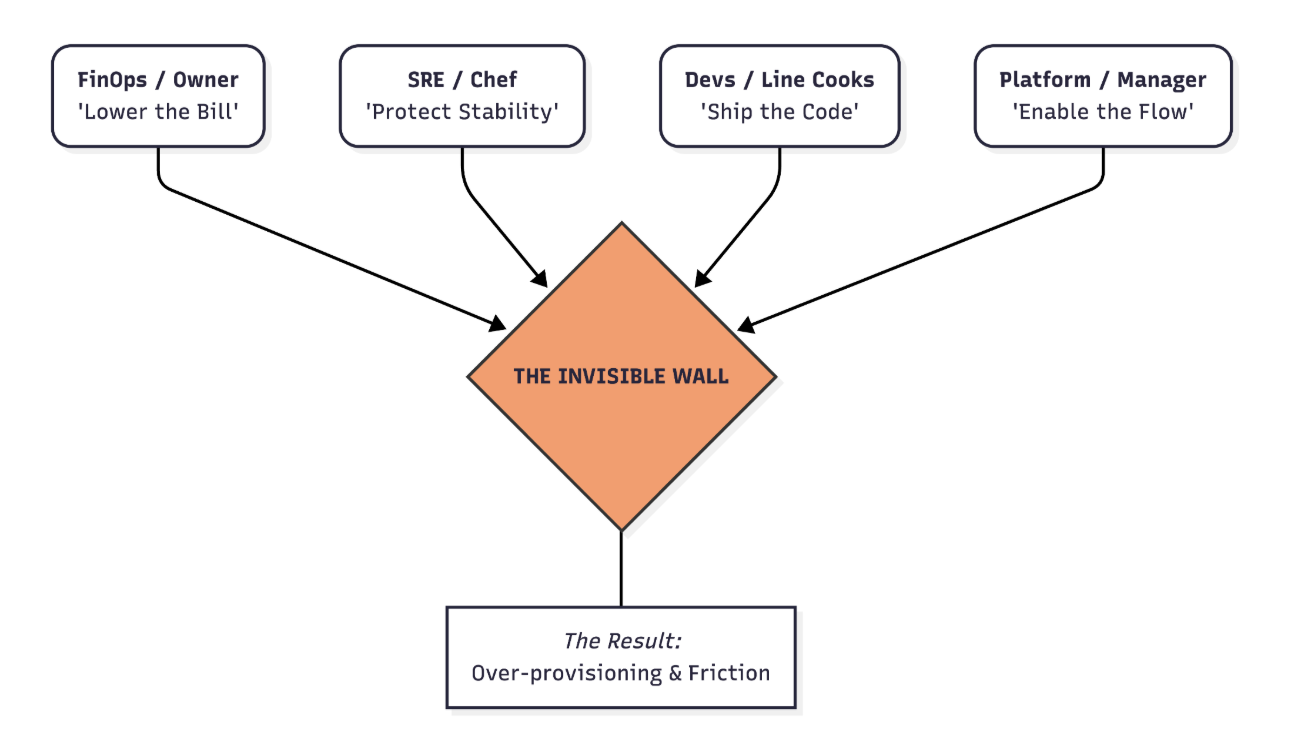
In the high-stakes world of cloud-native delivery, organizations are frequently paralyzed by an "invisible wall" that fundamentally separates FinOps professionals, Site Reliability Engineers, and Developers.
This structural friction strongly resembles a dysfunctional michelin-starred kitchen where the night’s success depends on characters who rarely see eye-to-eye on the operational priorities required to serve a flawless meal.
Because these highly specialized teams speak entirely different languages regarding risk and reward, this dynamic creates a zero-sum game where the organization must continuously trade off cost for reliability or speed for efficiency.
When a FinOps spreadsheet indicates that a Kubernetes pod is mostly idle, the SRE immediately perceives a threat to their carefully calculated reliability buffer, while the developers simply lack the contextual data to know how much compute space their specific application actually requires under realistic load.
This operational paralysis is further exacerbated by the shared ownership model prevalent in many modern enterprises, where a lack of singular accountability means that reactive cost-cutting and conservative over-provisioning remain the default strategies.
The day 2 operational gap
To break this destructive cycle, we must stop treating operational efficiency as a manual "spring cleaning" task and start recognizing it as an essential requirement that must be embedded deeply within modern platform architecture.
While the platform engineering community has excelled at creating golden paths to streamline the initial developer experience and deployment pipelines, the lifecycle of applications reaching production has been largely neglected. Currently, our primary method of assisting developers with post-deployment optimization relies on providing access to passive monitoring dashboards rather than delivering automated, actionable intelligence.
Organizations are striving to run highly performant applications while simultaneously maintaining strict cost controls and ensuring absolute reliability, but static golden paths are simply insufficient for managing this delicate trade-off.
When building deployment pipelines, everyone shares the single goal of releasing software, which allows for strict and opinionated automation. However, production optimization requires a highly configurable approach because different applications inherently require dynamic tuning strategies tailored to their specific risk profiles and performance needs. For these reasons, static deployment pipelines inevitably fall short during Day 2 operations and lead to systemic resource waste.
The full-stack optimization puzzle
True optimization represents a complex multi-layered puzzle that extends far beyond simply resizing Kubernetes pods or shutting down idle development environments after business hours.
Deep efficiency must begin at the application runtime level by tuning elements like the Java Virtual Machine heap size or garbage collection settings to ensure the core workload operates at peak health. Once the runtime is properly configured and understood, engineers can accurately size the container requests and limits to perfectly encase that specific application without causing artificial throttling or fatal memory errors.
This layered approach must also carefully incorporate how you scale horizontally and the underlying node groups to ensure the entire system remains stable when infrastructure density increases. Without looking at this vertical stack of dependencies, scaling policies might rely on superficial metrics that do not align with the newly established pod boundaries.
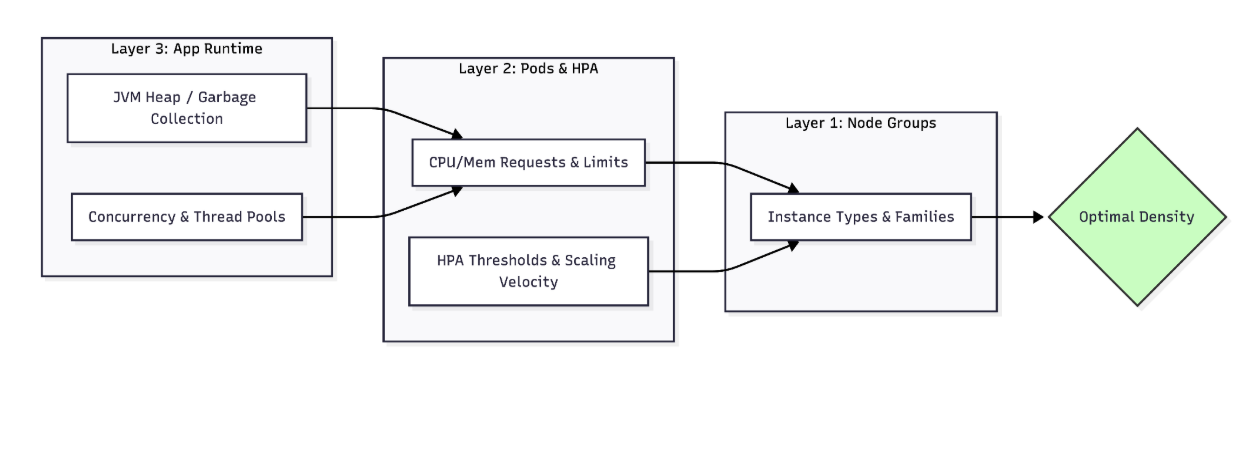
This inevitably causes the system to fluctuate unpredictably and degrade the performance of your applications. You cannot effectively optimize a system if you treat the container as an opaque black box, yet industry data shows that very few companies actually attempt to tune the container and the runtime in tandem.
Resolving the kitchen conflict
To solve this puzzle, we must address the conflicting motivations of the specialized roles mentioned earlier. The "invisible wall" persists because each player in the kitchen has a different definition of success:
- The FinOps team acts as the restaurant owner who scrutinizes every cloud expenditure and demands higher utilization rates to justify the infrastructure investments.
- The Site Reliability Engineers operate as the executive chefs who prioritize absolute uptime and system stability, often demanding massive resource buffers to absorb unexpected traffic spikes.
- The platform team serves as the overwhelmed manager attempting to standardize infrastructure while keeping the peace.
- The developers act as line cooks who desperately try to innovate without clear guidance on the resource constraints they must operate within.
Integrating efficiency into the GitOps workflow
By integrating performance gates directly into the continuous integration and continuous deployment pipeline, the platform team establishes a controlled environment where efficiency becomes a core component of the software release lifecycle.
These purpose-built platform capabilities can continuously analyze historical observability data to generate intelligent recommendations based on predefined tuning profiles that strictly respect the safety limits established by the SRE team.
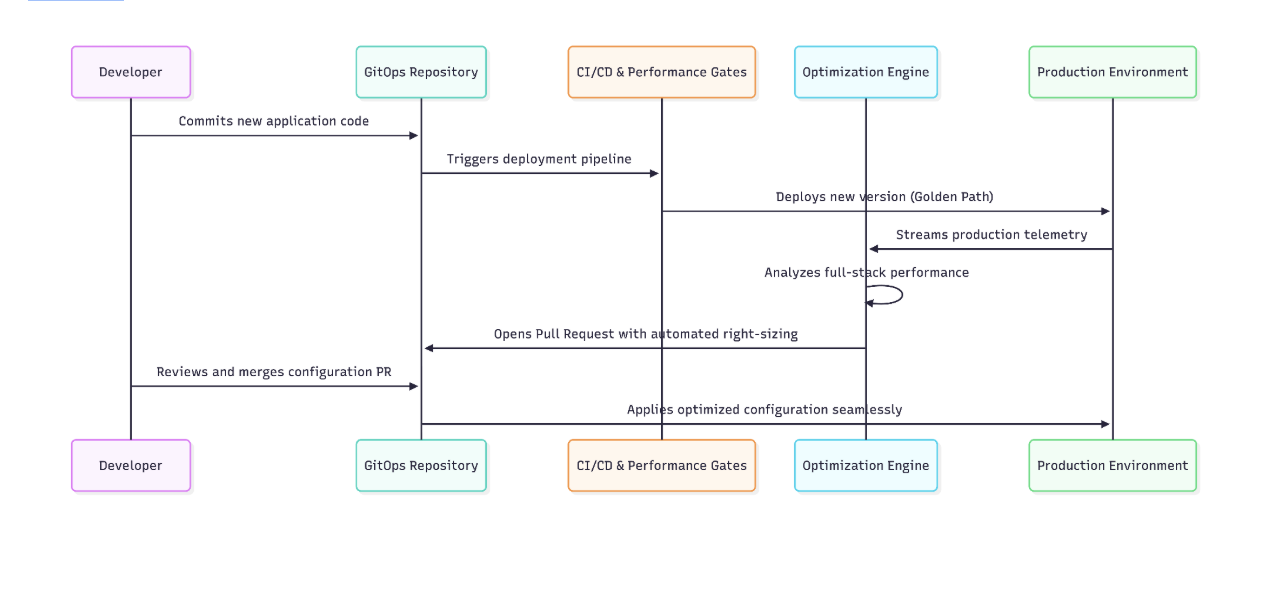
The most effective way to implement these data-driven recommendations involves establishing a human-in-the-loop workflow driven entirely through established GitOps principles. Whenever the platform identifies a more efficient configuration that satisfies both cost constraints and performance requirements, it seamlessly opens a pull request directly in the developer's repository containing the evidence-based sizing adjustments.
Developers can easily review these insights within their existing tools and approve the new configuration with absolute confidence, knowing that the proposed changes have been mathematically validated against the organizational reliability standards.
By embedding these automated right-sizing mechanisms directly into the golden path, the platform truly becomes a unified bridge that eliminates the historical friction between engineering departments. This approach moves the organization beyond simple infrastructure provisioning to create a self-improving ecosystem where cost-awareness and performance are continuously balanced without requiring constant human intervention.
By transforming optimization from a manual chore into an invisible platform capability, we solve the "Michelin kitchen" dilemma. This shift allows developers to focus entirely on innovation and feature delivery while the underlying system ensures the organizational menu is always perfectly optimized for both the business and the end user. When efficiency is automated, the invisible wall disappears, replaced by a seamless path toward sustainable, high-performance delivery.